.png)
在硬盘运维中,检测到坏道能否继续使用需要分层次处理,以下是专业角度的决策框架和操作方法:
一、坏道类型判断
1. 物理坏道(无法修复)
特征:
SMART报告中
Reallocated_Sector_Ct持续增长Pending Sector Count伴随Offline Uncorrectable上升硬件诊断工具(如PC-3000)检测到磁头/盘片物理损伤
2. 逻辑坏道(可能修复)
特征:
UDMA_CRC_Error_Count增加但无重映射文件系统错误(如ext4的
fsck报Inode bad blocks)低格/写零后可暂时恢复正常
二、处置决策树
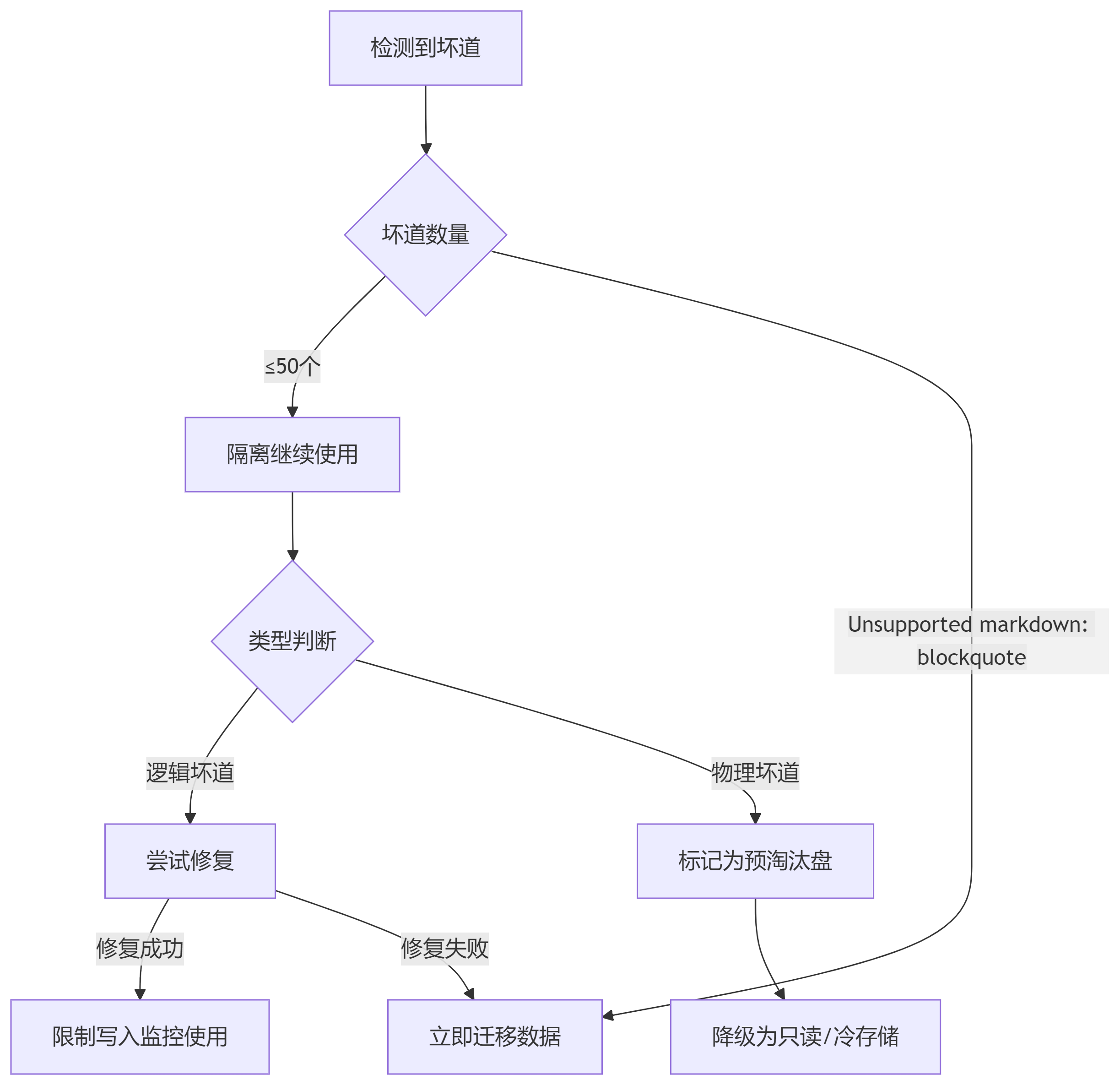
三、专业修复方法
1. 逻辑坏道修复流程
# 1. 强制重映射(Linux)
hdparm --repair-sector 0x1234 /dev/sdX # 单个扇区修复
badblocks -svw -t random /dev/sdX # 全盘写测试修复
# 2. 文件系统级隔离(ext4)
tune2fs -l /dev/sdX | grep Block # 查看块大小
debugfs -w /dev/sdX # 交互式标记坏块
> testb <block_number>
> clri <inode_number>
# 3. Windows工具
chkdsk /r /f X: # 自动修复+重映射
2. 物理坏道隔离方案
# 硬件RA卡隔离(以MegaRAID为例)
/opt/MegaRAID/storcli/storcli64 /c0/e252/s1 set offline
/opt/MegaRAID/storcli/storcli64 /c0/e252/s1 set good force
# ZFS专用处理
zpool scrub tank # 触发自动修复
zpool clear tank # 重置错误计数
四、临时使用规范
若必须继续使用带坏道的硬盘:
1.访问限制:
# 创建安全访问区域(示例:保留5%空间不分配)
parted /dev/sdX mkpart safe_start=$((100GB+5%)) safe_end=100%
mount -o noatime,nodiratime /dev/sdX3 /mnt/unsafe2.写入控制:
# 使用ionice+cgroup限制IO优先级
echo '8:16 5' > /sys/fs/cgroup/blkio/restricted_io/io.weight
ionice -c 2 -n 7 dd if=/dev/zero of=/mnt/unsafe/temp bs=1M count=1003.监控增强:
# 实时坏道增长监控脚本
while true; do
smartctl -A /dev/sdX | grep -E 'Reallocated|Pending|Uncorrectable'
iostat -xmd /dev/sdX 1 5 | grep -v '^$'
sleep 3600
done五、风险量化评估
六、企业级应对建议
1.HDD:
启用自动预拷贝(TLER/ERC设7秒)
在RAID6中降级为热备盘
配合前端缓存(如LVM cache pool)
2.SSD:
# 触发FTL重组(需厂商工具)
nvme format /dev/nvme0n1 -s1 -l1最终结论
可以短期使用的情况:
逻辑坏道已修复且24小时监控无新增
物理坏道<10个且不在系统关键区域(如GPT头)
必须立即停用的指征:
1周内新增坏道>5%
RAID阵列进入degraded状态
SMART 187 Reported_Uncorrect值突破阈值
建议搭配smartctl -t long /dev/sdX每周自检,并在所有含坏道的硬盘标签上标注"⚠ BAD BLOCK TRACKED"。对于存储重要数据的硬盘,任何类别的坏道都应触发数据迁移流程。